Nachdem ich meine Assist-Pipeline in Home Assistant eingerichtet habe und auch meine Home Assistant Voice Preview Edition läuft, wollte ich mich mit dem nächsten Thema beschäftigen. Durch einen externen LLM Provider können wir auch einen eigenen KI-Gesprächsagent in Home Assistant erzeugen. Mit diesem Thema will ich mich als heute beschäftigen.
Wir benötigen also zwei Komponenten, die Assist Pipeline und einen LLM Anbieter. Hier könnt ihr einen externen Anbieter verwenden oder z.B. eine eigene Ollama Instanz. Ich habe in diesem Beitrag gezeigt wie ich Ollama auf meine iGPU laufen lasse. Ich werde also meine eigene Ollama Instanz einsetzen um so fully local zu sein. Ich werde hier auch erst mal nur auf Konversationsagenten eingehen, KI-Tasks werde ich in einem extra Beitrag behandeln.
Beiträge aus der Assist Reihe:
- Assist – Der Sprachassistent von Home Assistant
- Ollama, Open WebUI und IPEX-LLM
- KI-Gesprächsagent in Home Assistant
- KI-Tasks in Home Assistant
Ollama Integration einbinden
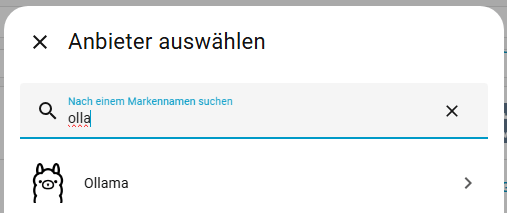
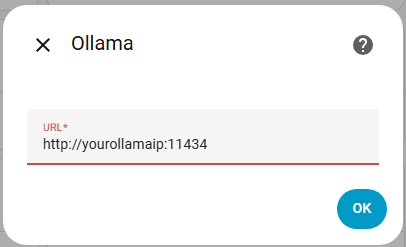
Wir beginnen damit die Ollama Integration einzurichten. Ihr wechselt dazu auf Einstellungen -> Geräte & Dienste -> Integration hinzufügen. Sucht nach Ollama und wählt die Integration aus. In dem folgenden Fenster gebt ihr die URL euerer Ollama Instanz an. Der Port ist normalerweise dabei 11434.
KI-Gesprächsagent einrichten
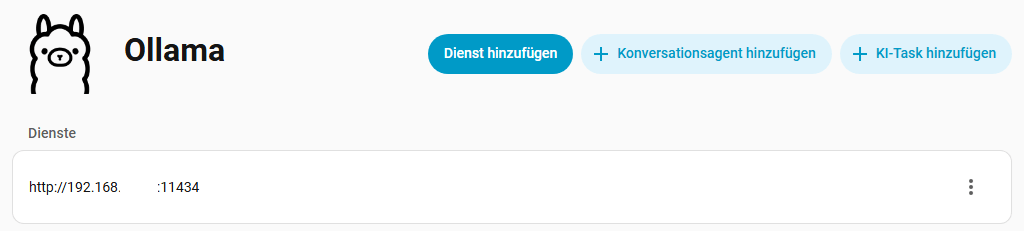
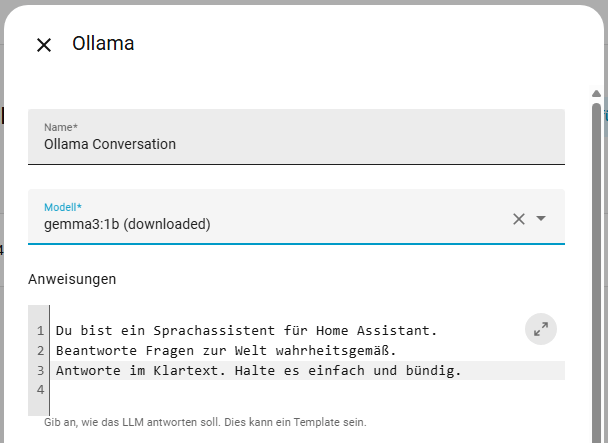
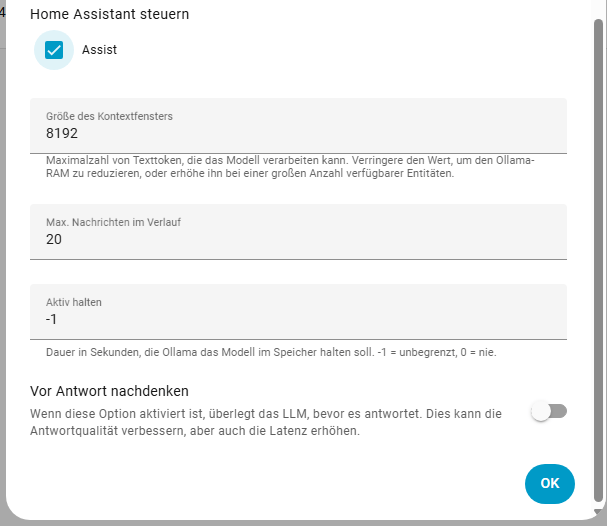
Nun können wir in der Ollama Integration einen Konversationsagenten hinzufügen. Vergebt eurem Agenten einen passenden Namen und wählt euer Modell aus. Wenn ihr bereits Modelle heruntergeladen habt, wird dieses auch angezeigt. In dem Feld Anweisung könnt ihr eurem LLM vorgaben machen, wie es antworten soll. Ihr könntet ihr z.B. sagen “ Du bist Mario. Sei lustig.“ Ihr könnt eurem Agenten erlauben ob der Home Assistant steuern darf. Die größe des Kontextfensters hat direkten Einfluss auf die Geschwindigkeit, probiert hier ruhig mal werte zwischen 2048 und 8192. Wenn ihr „Vor Antwort nachdenken“ aktiviert, dauert die Antwort am längsten.
KI-Gesprächsagentaktivieren
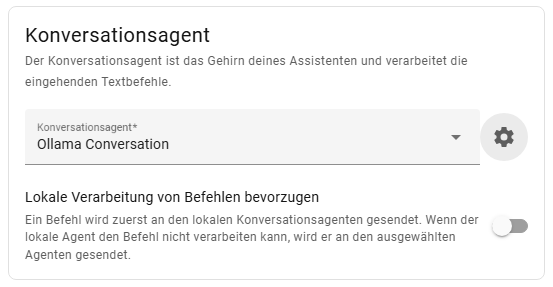
Damit der erstelle Agent auch genutzt wird, müsst ihr ihn auch aktivieren. Wechselt dazu in Einstellungen -> Sprachassistenten und wählt euren aktuellen Assistenten aus. Im Abschnitt Konversationsagent wählt ihr den nun zuvor erstellten Agenten. Um die Bearbeitungen von Befehlen in Home Assistant zu beschleunigen, würde ich die Option Lokale Verarbeitung bevorzugen aktivieren. Das war es dann auch schon, euer Agent ist fertig.
KI-Gesprächsagent testen
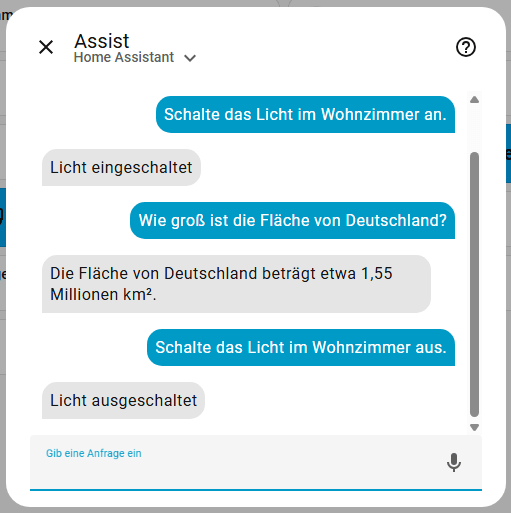
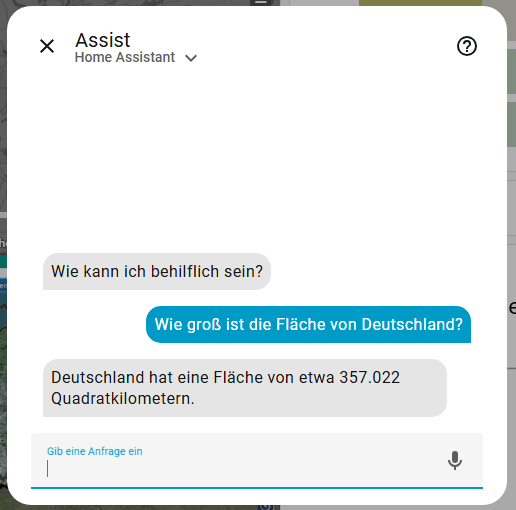
Öffnet nun Assist und stellt eure Frage. Home Assistant sollte euch nun auch Fragen zu anderen Themen beantworten können. Ok, die Antwort ist falsch, aber das liegt am verwendeten Model. Die Steuerung des Lichtes wurde hier lokal von Home Assistant erledigt. Mit qwen3:4b klappt es auch mit der Fläche, dauert aber länger.
Aufgetretene Probleme
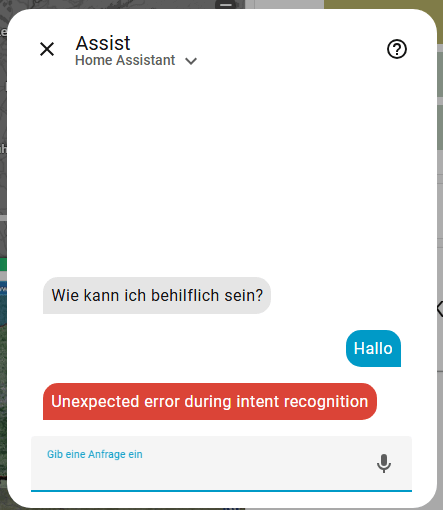
Folgende Fehlermeldung ist mir beim ersten Test über den Weg gelaufen. Ursache war das gewählte Modell. gemma3 unterstützt keine Tools und somit funktioniert es mit diesem Modell nicht. Ich habe zu qwen3 gewechselt und damit funktionierte die Abfrage sofort.
Damit haben wir Assist um einen weitere Baustein ergänzt. Auf meiner Agenda steht noch die Home Assistant Voice Preview Edition und KI Tasks.


