Oh man, ich bin echt hinten hinter. Ich habe mich kaum um Assist gekümmert und nun kommt das nächste große Thema. KI-Tasks oder auf englisch AI-Tasks, können eure Automatisierungen auf ein ganz neues Level heben. Dank ihnen können z.B. Bilder analysiert werde und ihr lasst euch über den Inhalt informiert. Ihr könnt euch somit darüber informieren lassen, wie viele Autos vor der Garage stehen. Genau so könnt ihr aber auch einen KI-Task verwenden um euch über bestimmte Themen, wie das Wetter, informieren zu lassen. Für mich ist das die größte Neuerung für Home Assistant in 2025 bisher und ihr solltet es euch wirklich mal anschauen.
Ich verfolge aktuell den Ansatz alles lokal zu halten und gehe daher hier auf die Konfiguration einer lokalen Ollama Instanz ein.
Beiträge aus der Assist Reihe:
- Assist – Der Sprachassistent von Home Assistant
- Ollama, Open WebUI und IPEX-LLM
- KI-Gesprächsagent in Home Assistant
- KI-Tasks in Home Assistant
KI-Task erzeugen
Wir können verschiedene KI-Tasks Entitäten anlegen, um die verschiedenen Aufgaben zu erledigen. So könnt ihr verschiedene Modelle Auswählen und nutzen. Ich werde in meinem Beispiel zwei KI-Task Entitäten erzeugen, eine für Bilderkennung, eine für Texterstellung.
Wir gehen nun zu Einstellungen -> Geräte & Dienste -> Ollama (bzw. euer LLM Provider) -> KI-Task hinzufügen. Für die Texterstellung nutze ich aktuell qwen3:4b und für die Bilderkennung qwen2.5vl:3b. Ich stehe mit dem Thema noch am Anfang und werde wohl noch ein paar Modelle testen müssen. Das Kontextfenster habe ich erst mal auf dem Default Wert gelassen und werde es später eventuell verringern. Über den Wert entity_id wird später der entsprechende KI-Task ausgewählt.
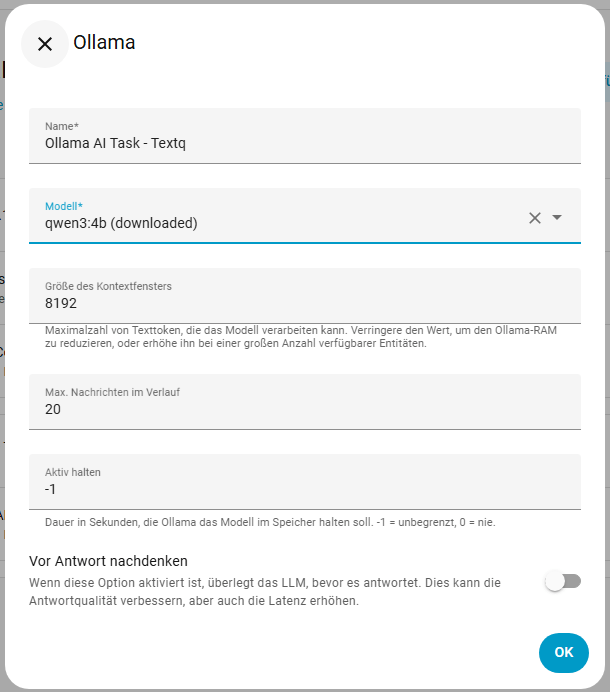
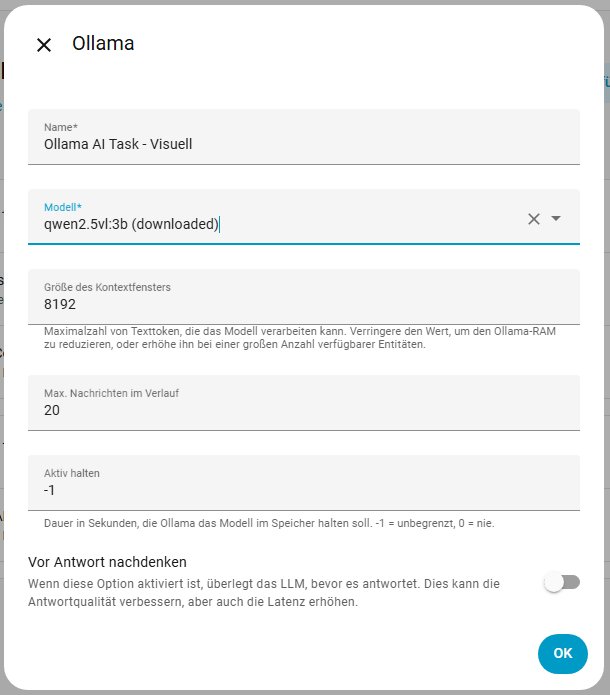
Automatisierung mit KI-Tasks ausstatten
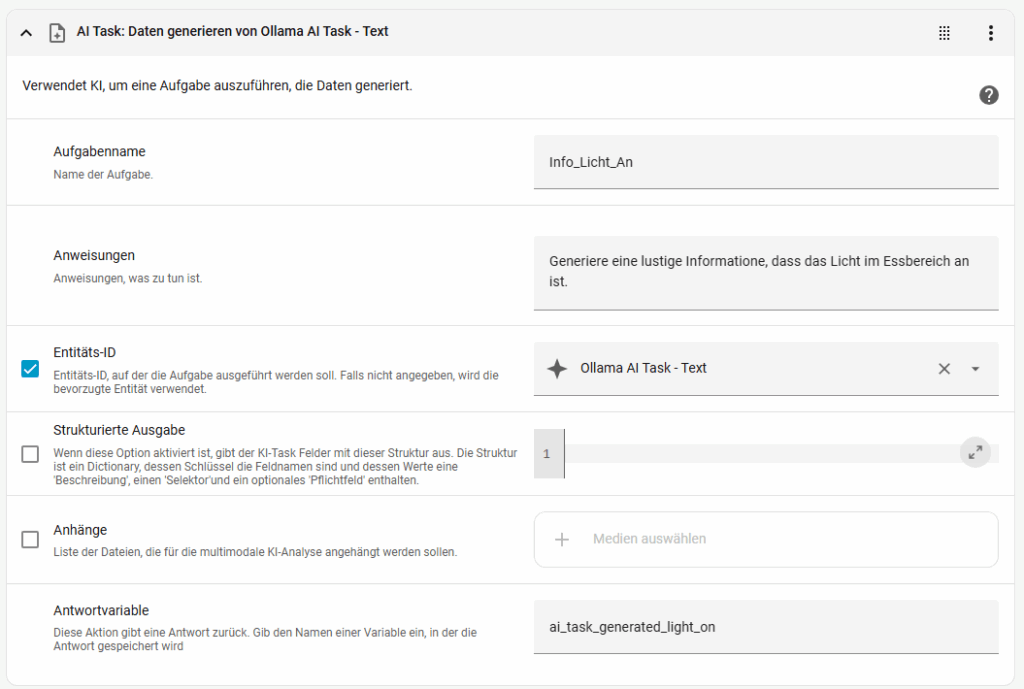
Um zu zeigen was jetzt möglich ist, habe ich diese Kurze Automatisierung erstellt. Sobald das Licht im Essbereich an geht, soll eine generierte Information auf mein Handy gesendet werden. Erst hat es nicht funktioniert, das war aber ein Performance-Problem. Ich habe das Modell auf qwen3:1.7b umgestellt und die Kontextlänge auf 4096 heruntergesetzt, damit lief es. Über die Qualität der Ergebnisse lässt sich streiten, aber es funktioniert. Darum geht es hier auch, ihr sollt sehen was möglich ist.


alias: AI-Task-Licht
description: ""
triggers:
- trigger: state
entity_id:
- light.essbereich
to: "on"
conditions: []
actions:
- action: ai_task.generate_data
metadata: {}
data:
entity_id: ai_task.ollama_ai_task_text
task_name: Info_Licht_An
instructions: >-
Generiere eine lustige Information, dass das Licht im Essbereich an
ist.
response_variable: ai_task_generated_light_on
- action: notify.mobile_app_fuagunn
metadata: {}
data:
message: "{{ ai_task_generated_light_on.data }}"
mode: single
AI-Tasks sind auch im visuellen Editor für Automatisierungen verfügbar, somit sollte das Erstellen für euch kein Problem sein.
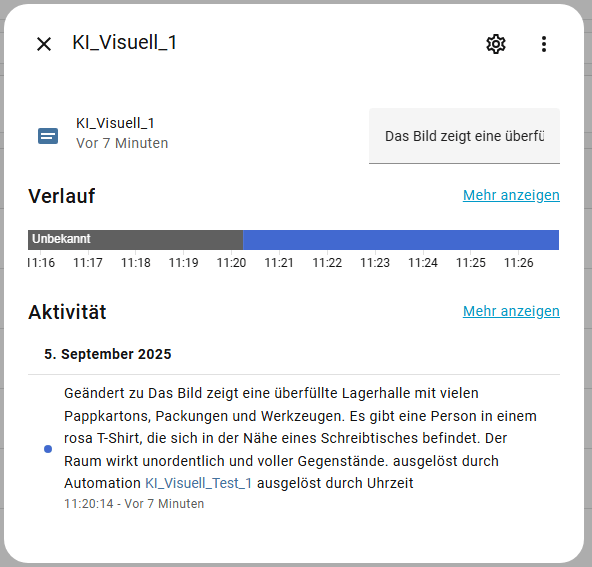
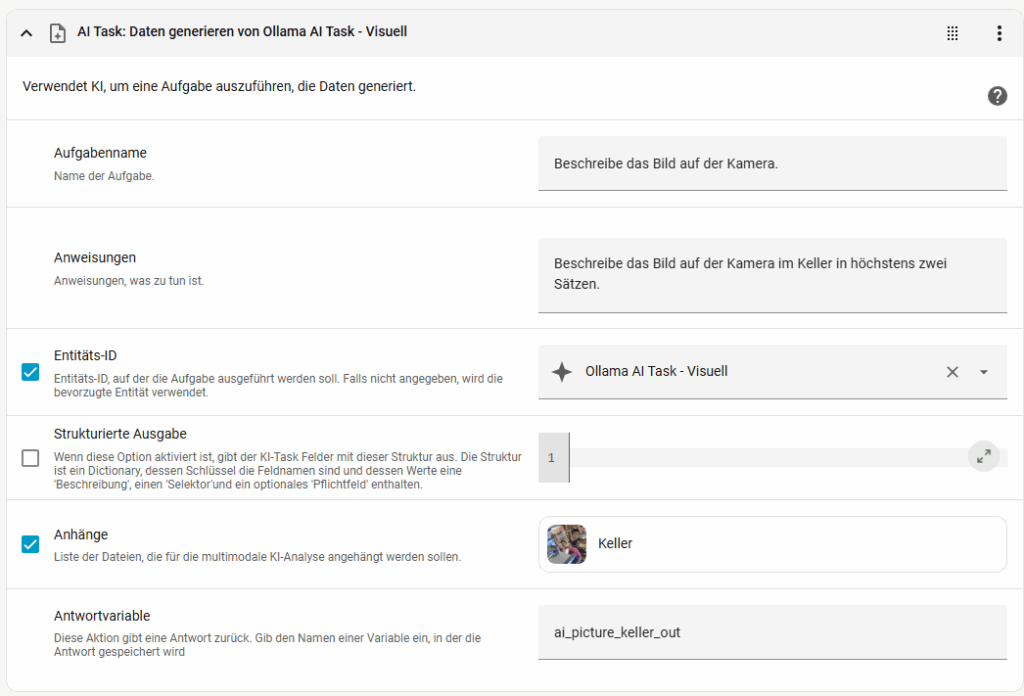
Wir haben aus einem Sensor, bzw. dem Zustand einer Entität Text erstellt. Nun gehen wir einen Schritt weiter und erstellen aus einem Bild eine Information. Ich habe hier ein Bild meiner Kamera im Keller und lasse eine Beschreibung durch den Task erstellen. Für Tests habe ich den Text in eine Text-Eingabe geschrieben, die Syntax ist dabei antwortvariable.data
Links seht ihr das Bild des Kellerraums und rechts die daraus generierte Beschreibung. Die KI meint ich müsste den Keller aufräumen 🙂

alias: KI_Visuell_Test_1
description: ""
triggers:
- trigger: time
at: "11:20:00"
conditions: []
actions:
- action: ai_task.generate_data
metadata: {}
data:
entity_id: ai_task.ollama_ai_task_visuell
attachments:
media_content_id: media-source://camera/camera.keller
media_content_type: application/vnd.apple.mpegurl
metadata:
title: Keller
thumbnail: /api/camera_proxy/camera.keller
media_class: video
children_media_class: null
navigateIds:
- {}
- media_content_type: app
media_content_id: media-source://camera
task_name: Beschreibe das Bild auf der Kamera.
instructions: Beschreibe das Bild auf der Kamera im Keller in höchstens zwei Sätzen.
response_variable: ai_picture_keller_out
- action: input_text.set_value
metadata: {}
data:
value: "{{ ai_picture_keller_out.data }}"
target:
entity_id: input_text.ki_visuell_1
mode: single
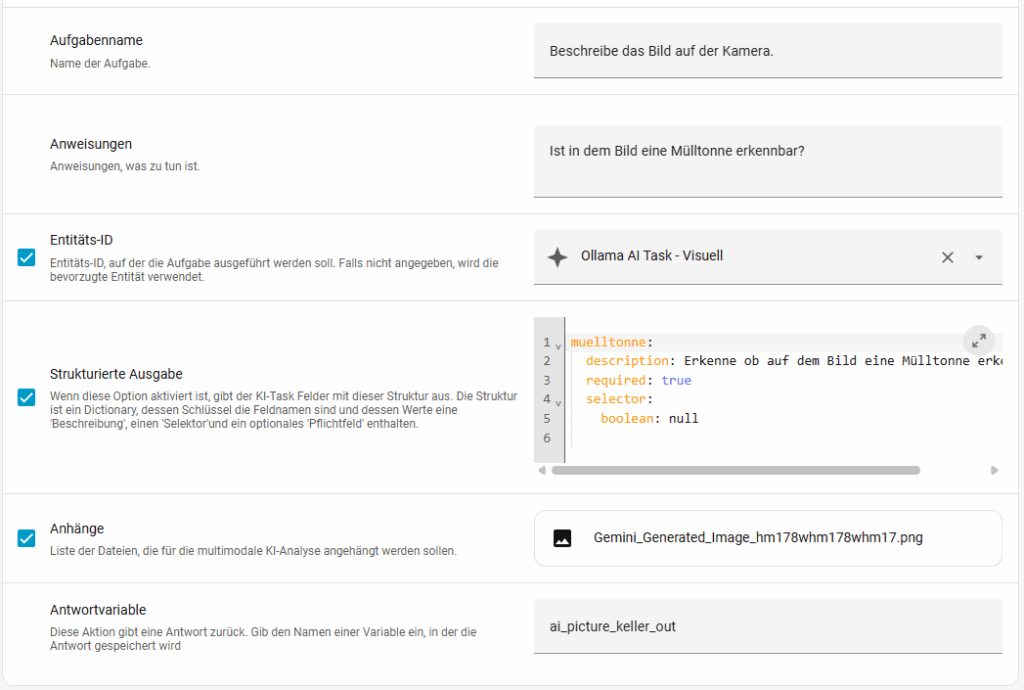
Über die strukturierte Ausgabe könnt ihr auch Werte und Zustände ausgeben lassen. Folgend seht ihr eine Übersicht über die drei Möglichen Varianten.
{
"yes_no_field": {
"description": "Description of the field",
"required": True/False, # Optional, defaults to False
"selector": {
"boolean": {} # Selector type
}
},
"text_field": {
"description": "Description of the text field",
"required": True/False, # Optional, defaults to False
"selector": {
"text": {} # Selector type
}
},
"number_field": {
"description": "Description of the number field",
"required": True/False, # Optional, defaults to False
"selector": {
"number": {
"min": 18, # Optional minimum value
"max": 100, # Optional maximum value
}
}
},
}Damit lasse ich nun ein Bild analysieren und mir zurückgeben ob eine Mülltonne erkennbar ist. Ich habe dieses mal ein KI generiertes Bild genommen. Wenn eine Mülltonne erkannt wird, schalte ich einen Helfer an und wenn sie nicht erkannt wird aus. Dieses soll nur ein Beispiel darstellen. Die Syntax ist dabei antwortvariable.data.feldname
alias: KI-Garbage
description: ""
triggers:
- trigger: time
at: "14:40:00"
conditions: []
actions:
- action: ai_task.generate_data
metadata: {}
data:
entity_id: ai_task.ollama_ai_task_visuell
attachments:
media_content_id: >-
media-source://media_source/local/Gemini_Generated_Image_hm178whm178whm17.png
media_content_type: image/png
metadata:
title: Gemini_Generated_Image_hm178whm178whm17.png
thumbnail: null
media_class: image
children_media_class: null
navigateIds:
- {}
- media_content_type: app
media_content_id: media-source://media_source
task_name: Beschreibe das Bild auf der Kamera.
instructions: Ist in dem Bild eine Mülltonne erkennbar?
structure:
muelltonne:
description: Erkenne ob auf dem Bild eine Mülltonne erkennbar ist.
required: true
selector:
boolean: null
response_variable: ai_picture_keller_out
- choose:
- conditions:
- condition: template
value_template: "{{ ai_picture_keller_out.data.muelltonne | default(false) }}"
sequence:
- action: input_boolean.turn_on
metadata: {}
data: {}
target:
entity_id: input_boolean.ki_garbage
- conditions:
- condition: template
value_template: "{{ not ai_picture_keller_out.data.muelltonne | default(false) }}"
sequence:
- action: input_boolean.turn_off
metadata: {}
data: {}
target:
entity_id: input_boolean.ki_garbage
mode: single

Genau so können wir dann auch Personen, in einem Bild, zählen. Ich übergebe die erkannten Personen an eine input_number Entität.
alias: KI-People
description: ""
triggers:
- trigger: time
at: "15:12:00"
conditions: []
actions:
- action: ai_task.generate_data
metadata: {}
data:
entity_id: ai_task.ollama_ai_task_visuell
attachments:
media_content_id: >-
media-source://media_source/local/Gemini_Generated_Image_c8i2kac8i2kac8i2.png
media_content_type: image/png
metadata:
title: Gemini_Generated_Image_c8i2kac8i2kac8i2.png
thumbnail: null
media_class: image
children_media_class: null
navigateIds:
- {}
- media_content_type: app
media_content_id: media-source://media_source
task_name: Beschreibe das Bild auf der Kamera.
instructions: Wie viele Personen sind erkennbar?
structure:
anzahl:
description: Wie viele Personen sind auf dem Bild erkennbar?
required: true
selector:
number: null
response_variable: ai_picture_keller_out
- action: input_number.set_value
metadata: {}
data:
value: "{{ ai_picture_keller_out.data.anzahl }}"
target:
entity_id: input_number.ki_people
mode: single
Dieses bietet uns wahnsinnig viele Möglichkeiten. Das was ich dabei gezeigt habe ist nur der Tropfen auf den heißen Stein. Mit den Tasks könnt ihr KI unterstützt eure Abläufe steuern oder euch Empfehlungen geben.

