2023 war das Year of the Voice und bisher habe ich das Thema Assist eher umrundet als aktiv angegangen. Ich habe ein paar versuche mit einem Atom Echo unternommen, was mich aber eher abgeschreckt hatte. Nun habe ich mich aber der Thematik nochmals angenommen und habe auf einem Testsystem alles nochmals durchgespielt. Wie ich das gemacht habe und was ich dabei gelernt habe, werde ich euch hier erzählen.
Mein Ziel ist es eine eine vollständig lokale Assist Pipeline einzurichten. Es besteht auch die Möglichkeit die Nabucasa Cloud zu nutzen, darauf gehe ich hier aber nicht ein.
Beiträge aus der Assist Reihe:
- Assist – Der Sprachassistent von Home Assistant
- Ollama, Open WebUI und IPEX-LLM
- KI-Gesprächsagent in Home Assistant
- KI-Tasks in Home Assistant
Hier mein System:
- Intel NUC mit 11th Gen Intel Core i5-1135G7 als Proxmox Server
- Home Assistant VM mit 6 Cores und 16GB (16GB aufgrund der Whisper language modells.)
- Home Assistant Operating System 16.1
- Home Assistant Core 2025.8.3
1. Speech-to-Text AddOn Whisper
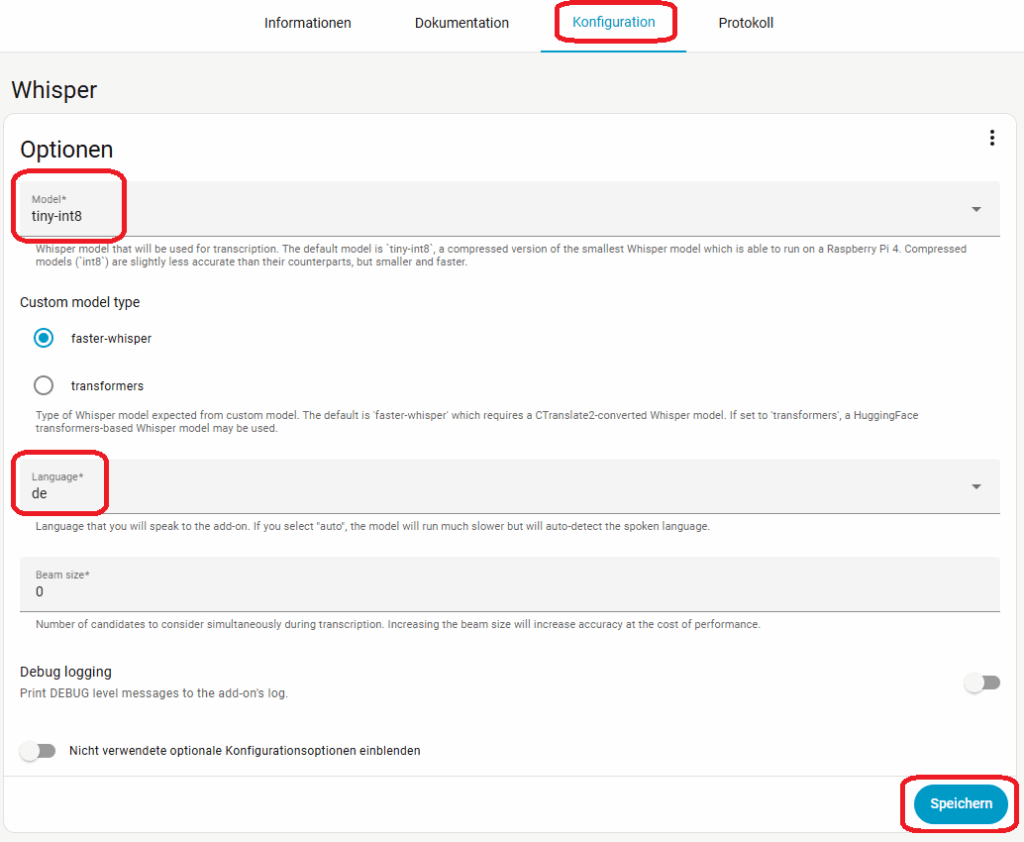
Den Anfang machen wir mit Whisper. Geht zu Einstellungen -> Add-ons -> Add-on Store. Sucht dort Whisper und installiert es. Unter Konfiguration wählen wir als Modell erst mal tiny-int8 und als Sprache de aus. Das Modell tiny-in8 ist zwar das ungenaueste aber auch das schnellste. Wir werden später noch andere Modelle testen, starten aber erst mal mit tiny-int8. Speichert die Konfiguration startet dann Whisper unter Informationen.
2. Text-to-Speech AddOn Piper
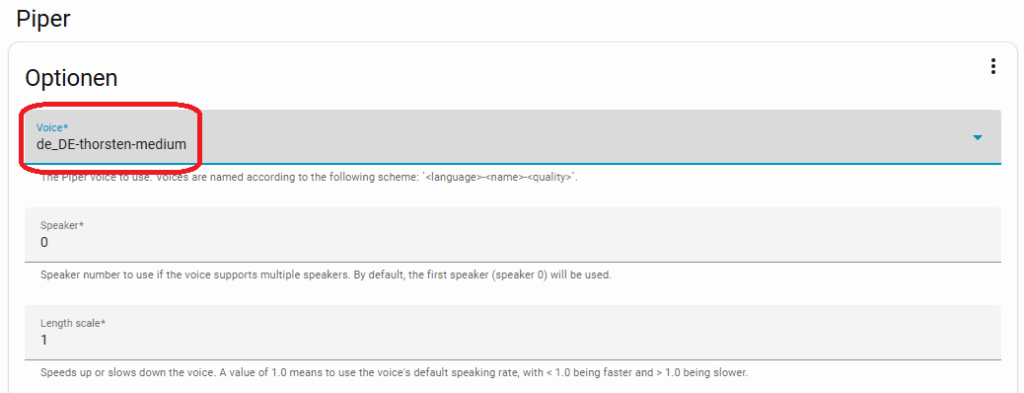
Das Gleiche machen wir nun mit Piper. In der Konfiguration wählt ihr unter Voice eine entsprechende Sprache. Ich habe mich für de_DE-thorsten-medium entschieden. Hier könnt ihr euch Beispiele anhören.
3. Integrationen hinzufügen
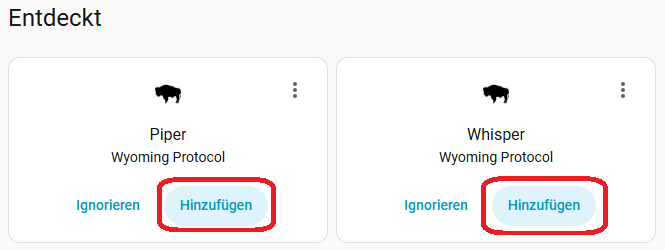
Wechselt nun zu Einstellungen -> Geräte & Dienste. Ihr seht, das Piper und Whisper automatisch durch die Wyoming Integration erkannt wurden. Fügt sie nun hinzu. Damit habt ihr beide Wege, also Sprache zu Text und Text zu Sprache eingerichtet. Diese bilden den Grundstein für euren Sprachassistenten.
4. Assist Sprachassistenten einrichten
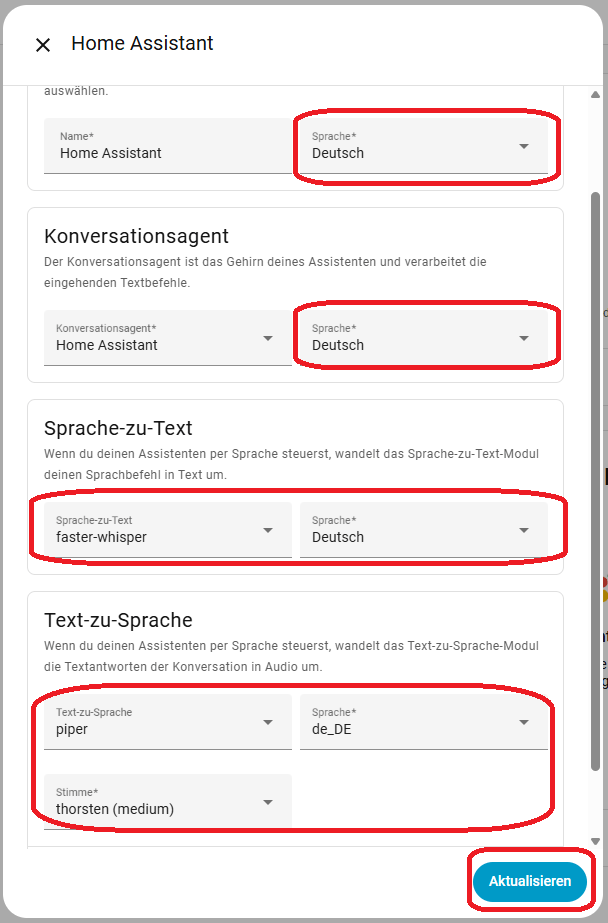
Nun kommen wir zum eigentlichen Sprachassistenten. Wechselt zu Einstellungen -> Sprachassistent. Wählt den Standard Sprachassistenten aus und passt die Einstellungen an. Als Sprache wählt ihr Deutsch und Whisper, bzw. Piper, für die jeweiligen Dienste.
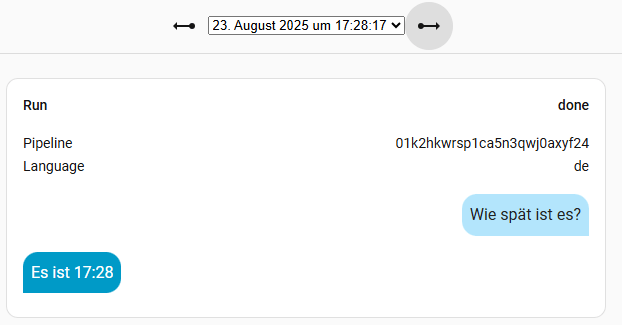
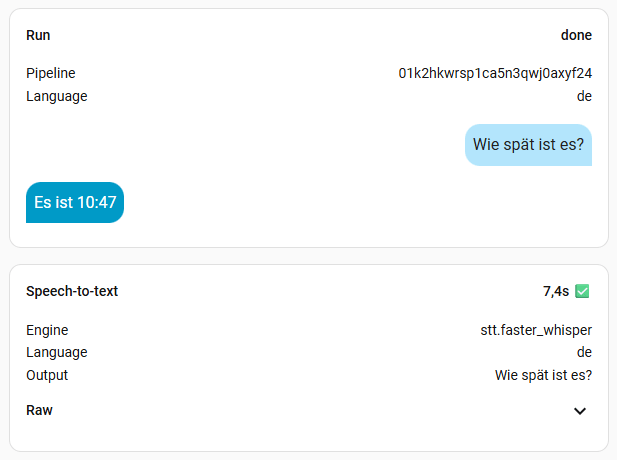
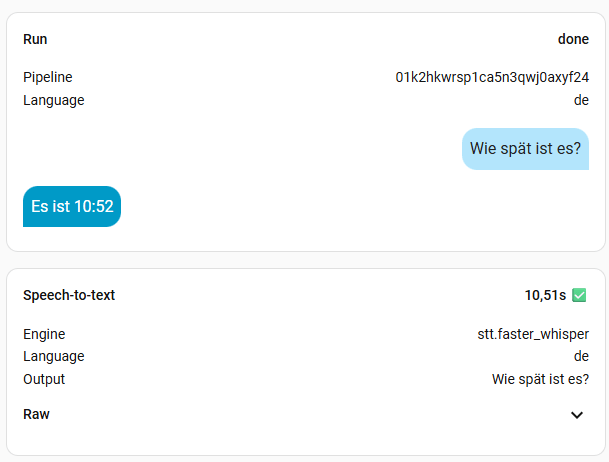
5. Assist testen mittels Debug
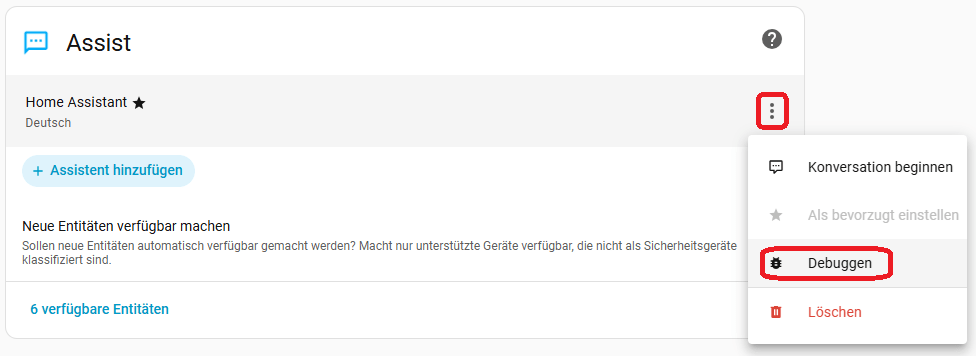
Über die Debug Funktion, könnt ihr Assist testen und auf Funktion überprüfen. Geht dazu auf die Menü-Buttons neben eurem Sprachassistenten und wählt Debug. Ihr könnt nun durch die letzten Konversationen blättern und die Daten anschauen. Oben rechts findet ihr ein Mikrofon-Symbol mit Sprechblasen. Hier könnt ihr eine Text- oder Audio-Pipeline ausführen. Um so beides zu testen. Am interessantesten ist die Bearbeitungszeit der Audio-Pipeline. Diese hängt stark von dem verwendeten Modell ab. Je größer das Modell, desto genauer, aber auch langsamer. Ihr müsst es einfach ausprobieren.
Anmerkung: Ein Voice-Test funktioniert nur über den Browser nur, wenn ihr eine https:// Verbindung aufbaut. Ansonsten funktioniert das Mikrofon nicht. Dieses Thema wird hier aber nicht behandelt und würde den Rahmen sprengen.
6. Entitäten freigeben
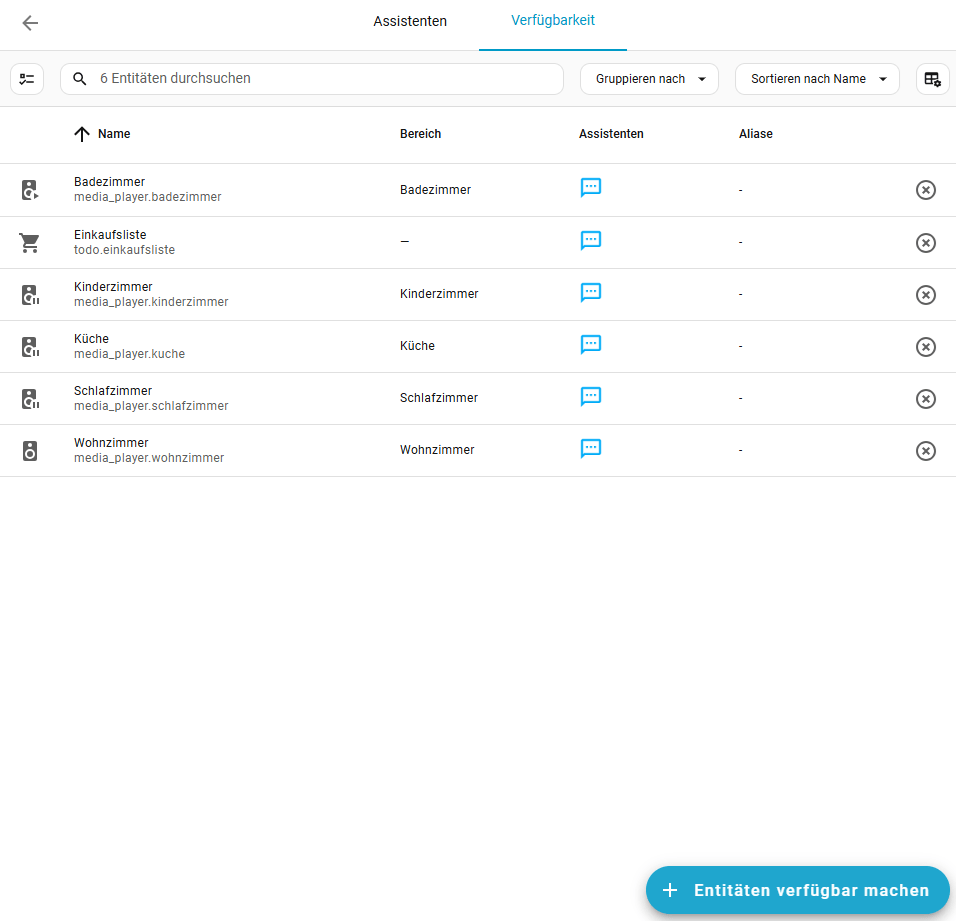
Damit Assist auch Zugriff auf eure Entítäten hat, müssen diese auch freigegeben sein. Ihr findet alle freigegebenen Entitäten unter Einstellungen -> Sprachassistenten -> Verfügbarkeit. Dort könnt ihr auch eure Entitäten direkt verfügbar machen, oder ihr aktiviert dieses direkt in der Entität selber. Dort kann auch ein Alias vergeben werden, damit die Entität über einen einfacheren Namen angesprochen werden kann. Dir Grundregel hier lautet, je weniger desto besser.
7. Areas und Floors
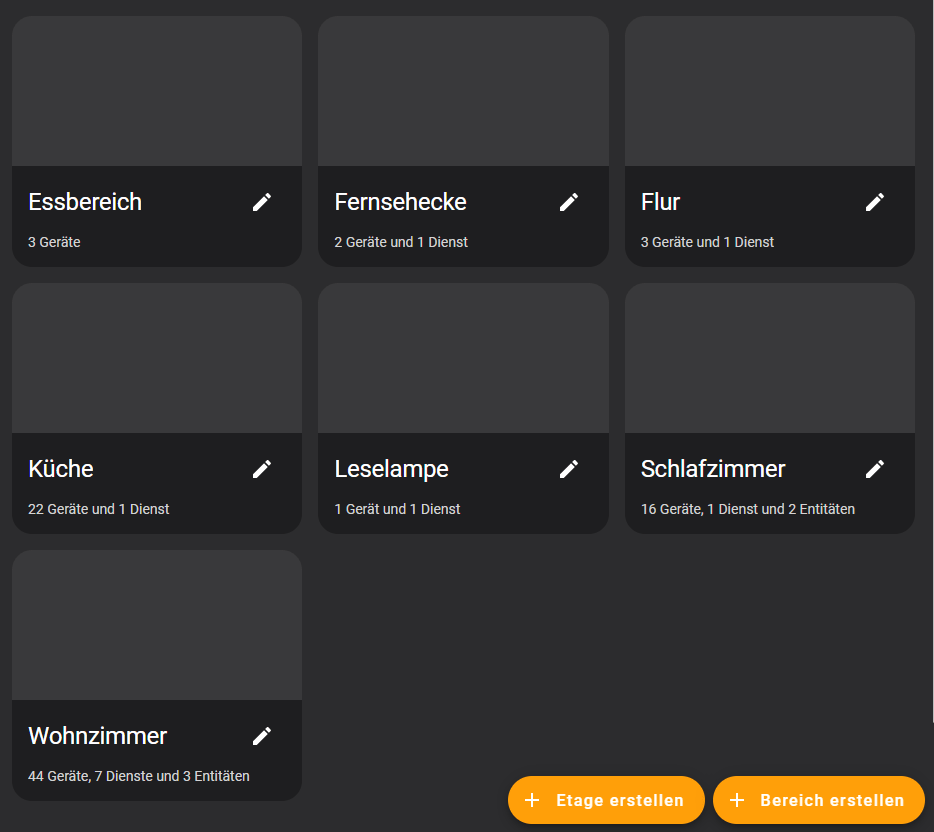
Ebenfalls sehr hilfreich ist es, alle Entitäten zu Bereichen und eventuell auch Etagen zugeordnet zu haben. Damit könnt ihr mehrere Lampen in einem Bereich gleichzeitig einschalten. Beides findet ihr unter Einstellungen -> Bereiche, Labels & Zonen. Hier könnt ihr euch einen Überblick über eure Bereich verschaffen und auch neue Anlegen. Eine Etage lässt sich ebenfalls erstellen.
Um den Bereich für ein Gerät zu ändern, wählt ihr dieses aus, drückt auf das Stift-Symbol oben rechts und passt den Bereich an.
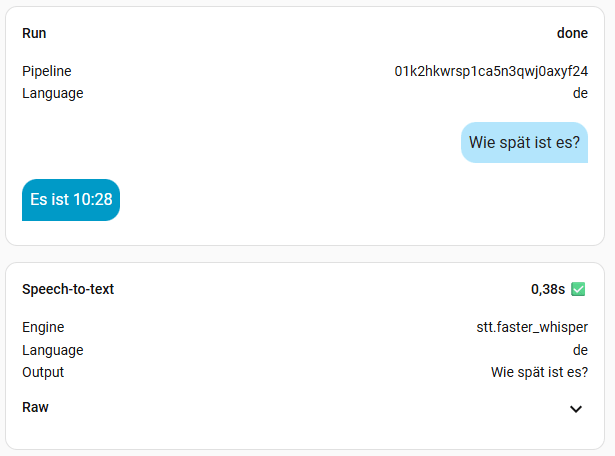
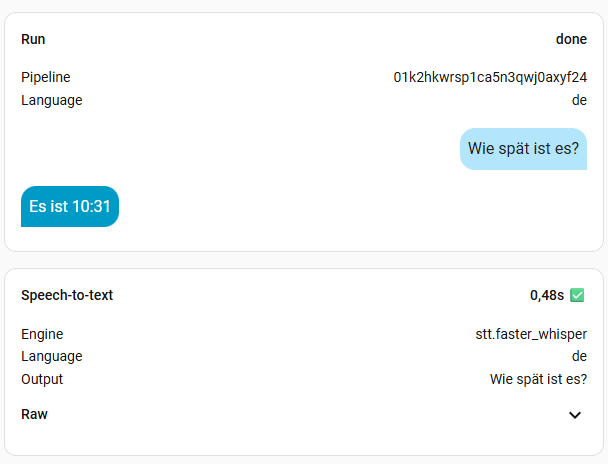
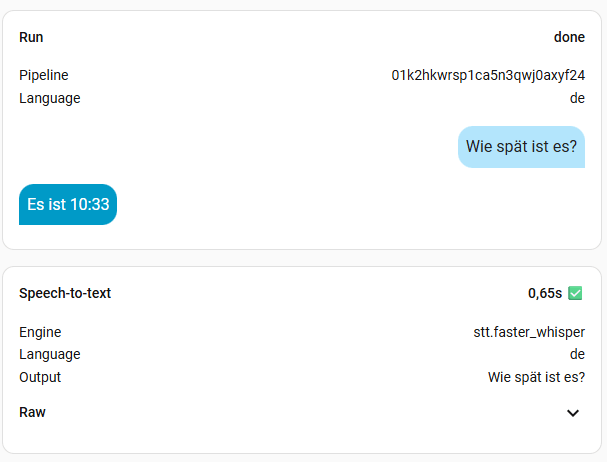
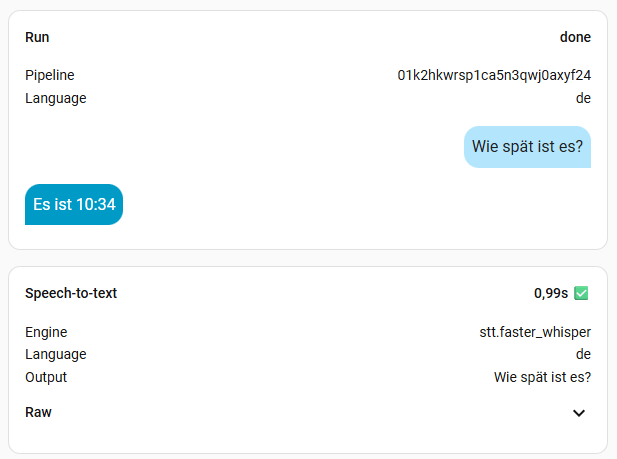
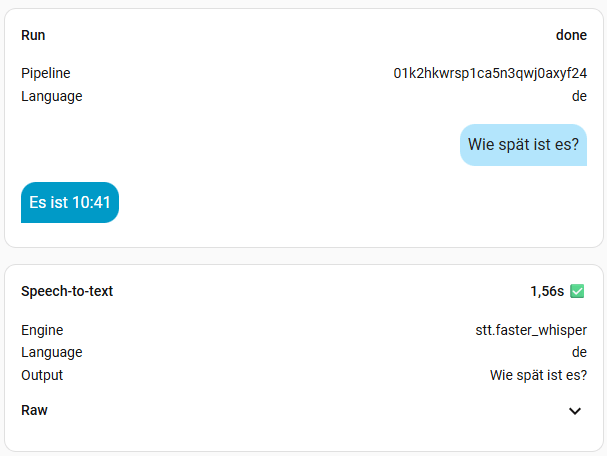
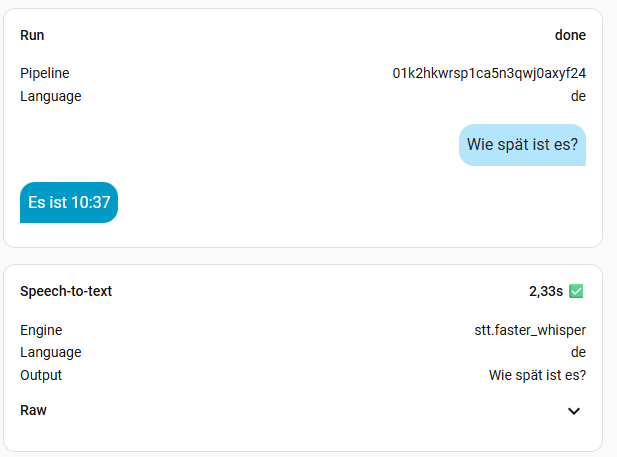
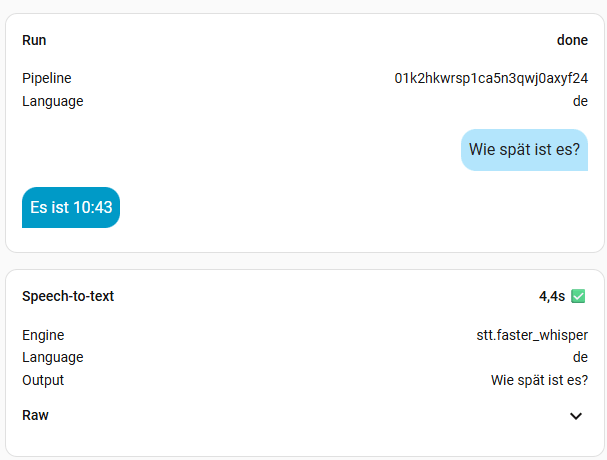
8. Benchmark
Ich habe mal alle Modelle, außer large durchgetestet. Die Frage war immer die Gleiche: „Wie spät ist es?“. Die kleinen Modelle sind sehr schnell, aber man muss sehr sauber sprechen. Das müsst ihr aber für euch selber ausprobieren, womit ihr klar kommt. Ich persönlich finde Zeiten bis zu einer Sekunde ok. Meine Modelle der Wahl sind also base oder small-int8, denn die kleineren haben mich oft nicht korrekt verstanden. Das hängt natürlich aber auch von der Hardware ab. Das turbo Modell soll eigentlich mit base vergleichbar sein, in der Geschwindigkeit, hat bei mir aber nichts gebracht. Vermutlich, weil Whisper bei mir zu 100% auf der CPU ausgeführt wird. Wer also eine richtige Grafikkarte mit CUDA nutzt, sollte hier viel bessere Werte erreichen. Bei mir wird mein Home Assistant aber wohl nie mehr als eine iGPU oder NPU zu sehen bekommen.
9. Assist nutzen

Ihr findet in der Companion App oder dem Webinterface das nebenstehende Symbol und könnt über Text und Voice (im Browser nur über https) mit Assist kommunizieren. Alles über euer lokales System, ohne eine Ableitung der Daten nach Außerhalb. Zusätzlich könnt ihr noch externe Hardware nutzen, welche die Voice Daten an Home Assistant Assist liefert. Diese werden über eine Wake Word aktiviert, wie „Okay Nabu“. Beispiele dafür wären:
Das Ziel von Home Assistant ist es, das jeder Assist lokal nutzen kann.
10. Aussicht
Ich werde mit die Home Assistant Voice Preview Edition besorgen und weiter testen, dann auch noch mit openWakeWord. Zusätzlich werde ich Ollama integrieren und einen KI Sprachassistenten erzeugen. Also bleibt dran und verfolgt wie es weiter geht. In der Zwischenzeit könnt ihr euch mal die Best practices with Assist anschauen.


