
In meinem Artikel über Home Assistant Assist hatte ich ja bereits angekündigt, mich mit einem KI Sprachassistenten zu beschäftigen. Da alles lokal ablaufen soll, muss eine entsprechendes LLM her. Home Assistant unterstützt Ollama und somit liegt es nahe Ollama zu nutzen. Ollama kann komplett über die CLI genutzt werden, aber Open WebUI als GUI macht es etwas einfacher.
Da ich Proxmox nutze, wäre bis hier das Einfachste, einfach einen LCX Container zu erzeugen. Dank diesem Proxmox Helper-Script, ist das Thema schnell erledigt. Die Installation ist selbsterklärend und kann später in Home Assistant eingebunden werden.
Ich möchte jedoch etwas weiter gehen. In meinem Intel NUC, steckt ein 11th Gen Core i5 mit einer Iris Xe GPU. Diese iGPU wird aktuell nicht genutzt. Anstelle also die Berechnung auf der CPU auszuführen, will ich diese auf die iGPU verschieben. Dadurch belaste ich die CPU viel weniger, behalte die Leistung für die VMs und nutze endlich die iGPU. Intel selber liefert dafür die nötige Software.
Ich setzte dabei zu 100% auf die Arbeit von Nikolay Falaleev, der Ollama, Open WebUI und Intel IPEX in ein Projekt gepackt hat. Ich möchte euch lediglich hierzu eine Anleitung liefern. Es gibt sicherlich noch weitere Methoden, diese war für mich aktuell aber die einfachste und erfolgreichste.
Ich möchte vorab etwas zur Performance sagen. Gegenüber der CPU, habe ich mit der iGPU Variante ca. 15 bis 25% weniger Leistung. Der große Vorteil liegt aber darin, die CPU frei zu halten und die bisher unnütze iGPU zu nutzen. Genug geredet, lasst uns anfangen
Beiträge aus der Assist Reihe:
- Assist – Der Sprachassistent von Home Assistant
- Ollama, Open WebUI und IPEX-LLM
- KI-Gesprächsagent in Home Assistant
- KI-Tasks in Home Assistant
1. Vorbereitungen
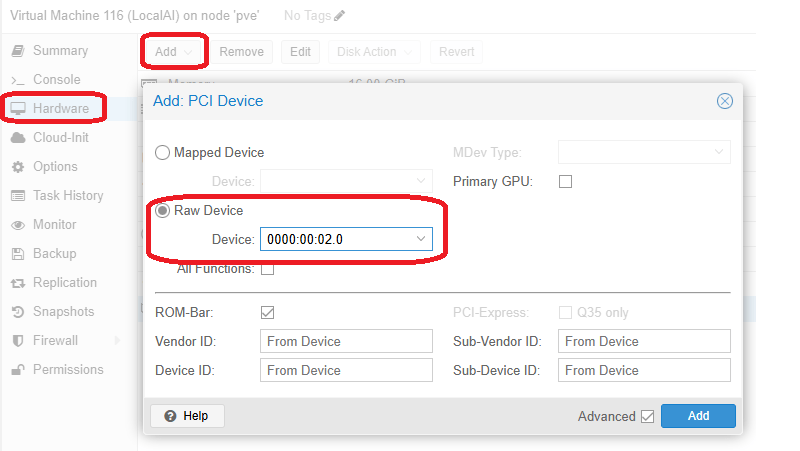
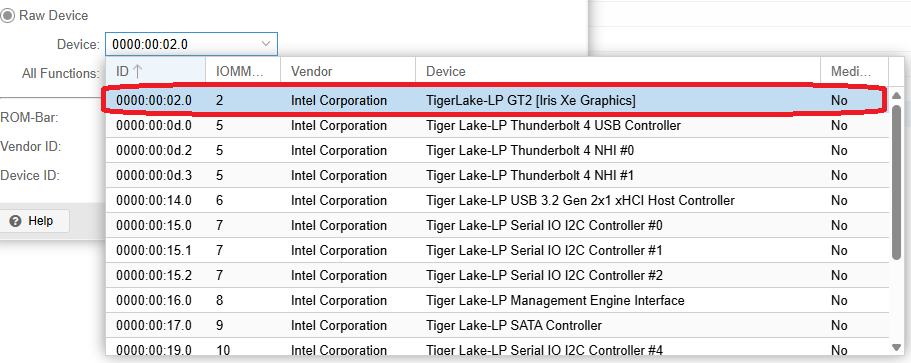
Wir beginnen damit eine VM bereitzustellen. Ich habe eine Debian 13 VM erstellt, der ich 6 Cores und 16GB zugeteilt habe. Zusätzlich reichen wir die iGPU an die VM weiter. Dazu wählt ihr unter Hardware Add PCI Device und fügt die Grafikkarte hinzu. Eine grafische Oberfläche brauchen wir nicht, denn wir erledigen alles im Terminal. Da wir 16GB zugeteilt haben, kann die iGPU maximal 8 GB nutzen, denn es geht immer maximal die Hälfte. Ich plane auch nur <=4B Modelle zu verwenden, da bei größeren Modellen die Bearbeitungszeit zu lange ist. Wer also größere Modelle fahren möchte, sollte auch entsprechend RAM zur Verfügung stellen.
Mit 16GB könnt ihr jedenfalls mehrere Modelle, wie gemma3:4b und qwen3:4b, in die iGPU auslagern.
2. Docker installieren
Die Arbeit von Nicolay verwendet Docker Container, somit müssen wir erst mal Docker installieren. Ich führe alle Befehle als root aus. Solltet ihr diese als nicht root User ausführen wollen, müsst ihr sudo voranstellen. Wir beginnen damit den Docker GPG Key hinzuzufügen.
apt update
apt install ca-certificates curl
install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc
chmod a+r /etc/apt/keyrings/docker.ascNun fügen wir das Docker Repository hinzu und aktualisieren die Paketquellen.
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
tee /etc/apt/sources.list.d/docker.list > /dev/null
apt updateNun können wir endlich Docker installieren.
apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin3. Grafiktreiber installieren
Damit wir die iGPU überhaupt nutzen können, müssen wir dafür noch Treiber installieren. Den zweiten Befehl müsst ihr ebenfalls nach jeder Kernel Aktualisierung durchführen
apt install firmware-misc-nonfree firmware-intel-graphics
update-initramfs -u -k allNicht notwendig, aber sehr nützlich sind die Intel GPU Tools. Damit könnt ihr die Auslastung der GPU überprüfen und seht somit ob der Offload klappt. In dem Beispiel sieht man das Ollama bereits ein Modell mit knapp 1GB geladen hat und aktuell idle ist.
apt install intel-gpu-tools
intel_gpu_top
4. Die Container installieren
git clone https://github.com/NikolasEnt/ollama-webui-intel
cd ollama-webui-intel
docker compose build
docker compose up -dMit den Befehl docker ps solltet ihr nun zwei Container sehen. Warte bis diese beide den Status healthy erreicht haben und dann geht es weiter.
5. Open WebUI und Ollama
Nun sind wir fast fertig. Wir müssen jetzt noch Modelle laden und können dann auch schon unsere erste Anfrage stellen. Open WebUI erreicht ihr nun unter http://eureIP:18080/ . Beim ersten Öffnen, werdet ihr nach eurem Namen, Email und Passwort gefragt. Damit habt ihr dann auch schon einen lokalen Account erzeugt.
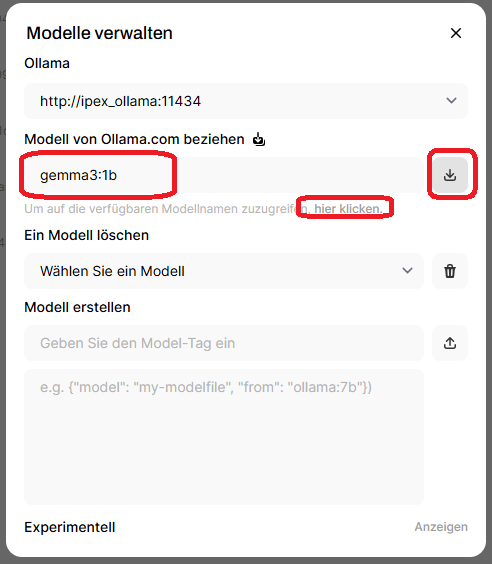
Geht nun auf das User Icon und öffnet Einstellungen. Dort wählen wir Administration und gehen auf Modelle. Nun können wir die hier verfügbaren Modelle laden. Ich würde für den Angang gemma3:1b und qwen2.5:1.5b empfehlen. Kleiner geht natürlich auch, ist sogar schneller, aber auch ungenauer. Testet es einfach mal aus und gebt euren ersten Prompt ein. Dabei solltet ihr mittels intel_gpu_top prüfen ob ihr auch die iGPU verwendet.
Unter Verbindungen könnt ihr noch OpenAI abschalten und unter Evaluationen die Arena-Modelle.
dsddsd

6. Startup Script
Nach einem Reboot, startet der Intel-IPEX Container nicht automatisch. Ich habe dafür ein Script angelegt, welches 10 Sekunden nach dem Boot ausgeführt wird. Mittel vi /root/docker.sh habe ich ein Script erzeugt, welches folgenden Inhalt hat. Anschließend muss das Script noch, mit chmod +x /root/docker.sh, ausführbar gemacht werden. Ich müsst natürlich die Pfade an eure Gegebenheiten anpassen.
cd /root/ollama-webui-intel/
docker compose up -dFolgenden Zeile habe ich danach mittels crontab -e in das root crontab eingefügt.
@reboot sleep 10 && /root/docker.shIch hoffe ich konnte euch weiter helfen. Als nächstes geht es dann mit Home Assistant wieder weiter.