Da ich einen neuen Beitrag zu Node-RED ind InfluxDB V2.x erstellt habe, muss nun auch ein Beitrag zu Grafana und InfluxDB V2.x her. Ich gehe hier auch auf ein paar allgemeine Dinge ein, die ihr auch in Node-RED einsetzen könnt. Es steht zwar InfluxDB Edge vor der Tür, welches die Version 3.x darstellt und wieder eine Syntax nach SQL nutzt, aber schaden kann das hier nicht.
Ich gehe nicht auf die Installation von Grafana oder InfluxDB ein, das setzte ich als bereits erledigt voraus. Wir starten mit dem API-Key und machen dann mit der Konfiguration von InfluxDB als Datasource in Grafana weiter.
API-Token in InfluxDB erzeugen
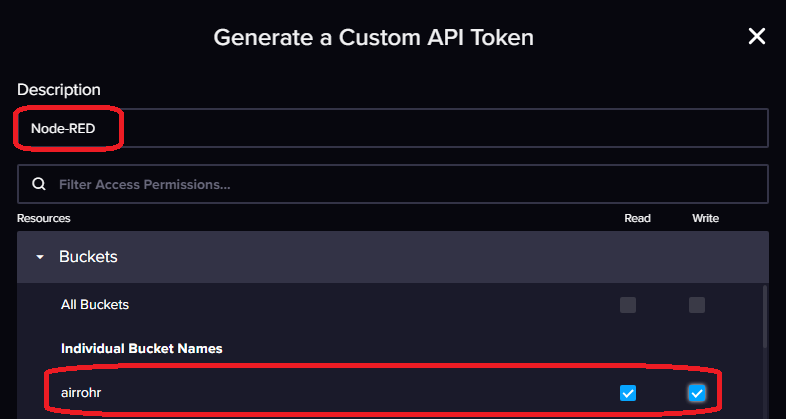
Wie bereits in dem vorhergehenden Beitrag gesehen, müssen/sollten wir einen separaten API-Token für Grafana erzeugen, der auch nur Lese-Rechte benötigt. Nehmt euren Browser und öffnet das Webinterface eurer InfluxDB Instanz unter http://ip-eures-influxdb-servers:8086 und loggt euch ein. Load Data -> BUCKETS -> API TOKENS könnt ihr ein neues Token erstellen. Ihr solltet dabei „Custom API Token wählen“. Ihr könnt zwar ein „All Access Token“ erzeugen, das ist aber sicherheitstechnisch nicht empfehlenswert. Ihr solltet pro Anwendung ein Token vergeben, mit nur den benötigten Rechten. Wählt also „Custom API Token“ und vergebt einen Namen. Unter Ressources wählt ihr euren Bucket und vergebt die Read Permission. Anschließend bestätigt ihr mit Generate. Kopiert euch das nun angezeigt API Token, denn dieses ist quasi das Passwort welches Grafana für den Zugriff auf InfluxDB, nutzen wird.


Data Source in Grafana erzeugen
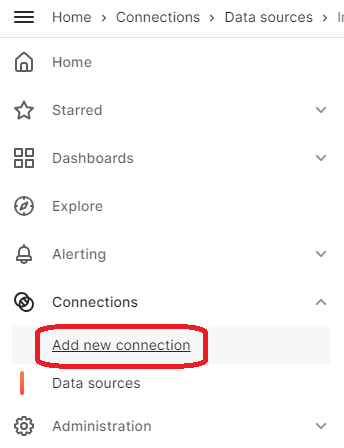
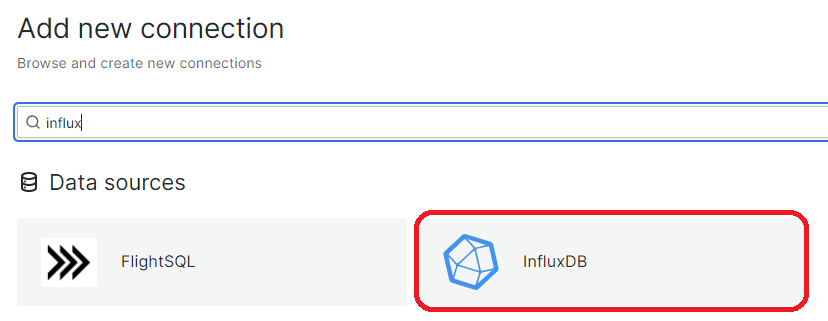
Damit Grafana auf die Daten aus InfluxDB zugreifen kann, müssen wir diese als Datenquelle definieren. Wählt im Menü den Punkt Connections und Add new connection. Sucht nach influx, klickt auf InfluxDB und bestätigt dieses mit Add new data source.

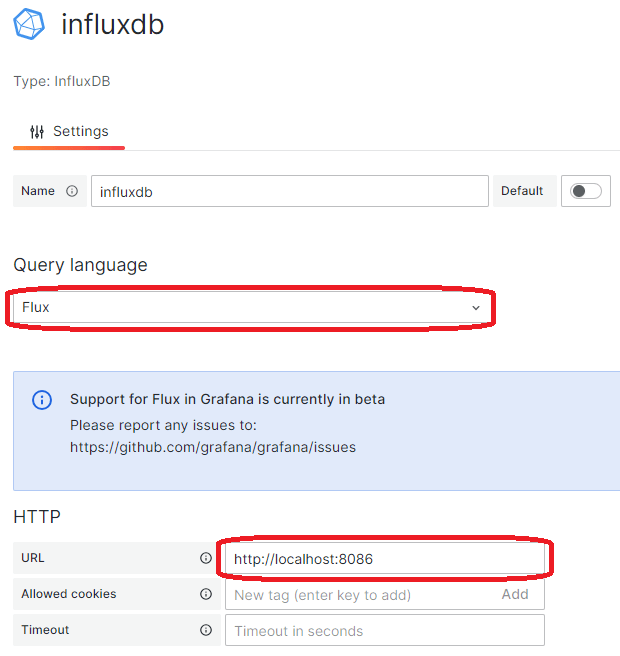
Nun müssen wir die eigentliche Datenquelle konfigurieren. Vergebt einen Namen und wählt als Query language Flux aus. Die URL muss auf euren InfluxDB Server verweisen Unter Auth sollte nichts aktiviert sein und unter InfluxDB details müsste ihr eure Organisation, das Token für Grafana und einen Default Bucket setzern.
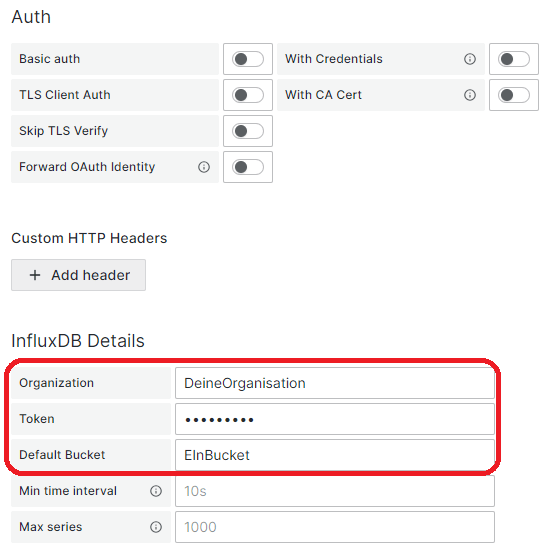
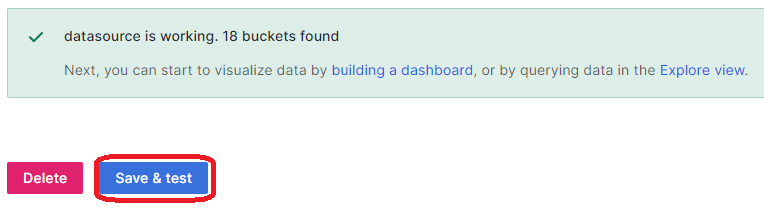
Abschließend bestätigt ihr eure Eingaben mit dem Button Save & test. Anschließend solltet ihr mit einer positiven Bestätigung informiert werden.
Dashboard und die erste Abfrage erstellen
Der beste Weg um seine erste Flux Abfrage zu erstellen, führt über den Data Explorer von InfluxDB. Hier könnt ihr euch einfach durch eure Buckets, Measurements und Fields klicken und der Query Builder erstellt eine Abfrage.
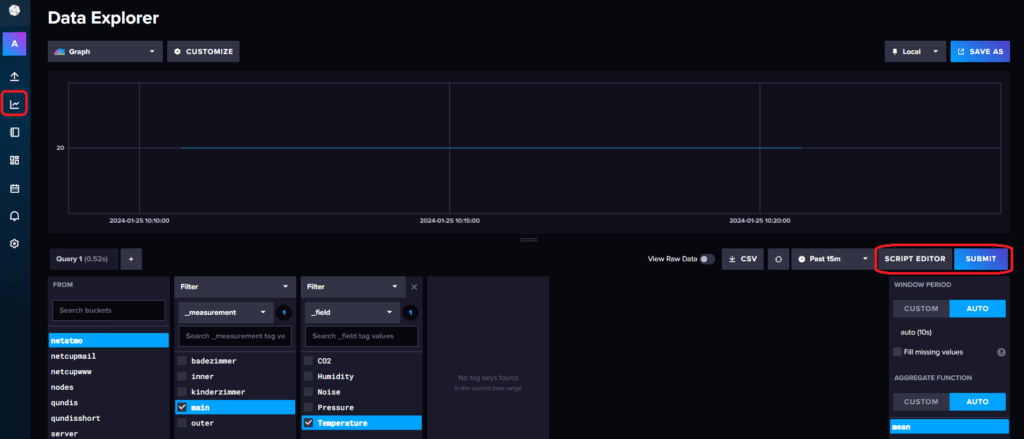
Wenn ihr nun auf den Script Editor Button drückt, erhaltet ihr die fertige Abfrage. Diese kann auch so direkt in Grafana eingebunden werden. In diesem Fall werden die Daten aus dem Bucket „netatmo“ gelesen, mit dem Measurement „main“ und das Feld „Temperature“.
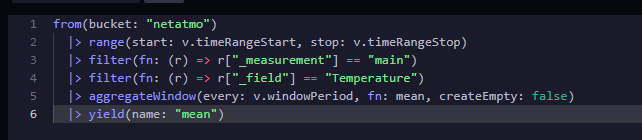
from(bucket: "netatmo")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "main")
|> filter(fn: (r) => r["_field"] == "Temperature")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")Das aggregateWindow berechnet den Durchschnittswert im Intervall. Das Intervall ist abhängig von der Breite des Panels (entspicht den maximalen Datenpunkten) und des Betrachtungszeitraums. Datenpunkte / Betrachtungszeitraum = Intervall.
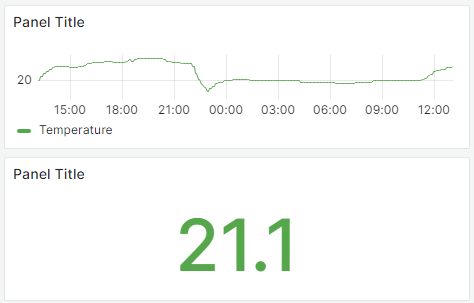
Wenn ihr nur einen einfachen Wert braucht, dann könnt ihr auf das aggregateWindow verzichten und den letzten Wert ausgeben lassen.
from(bucket: "netatmo")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "main")
|> filter(fn: (r) => r["_field"] == "Temperature")
|>last()Weitere Abfragen
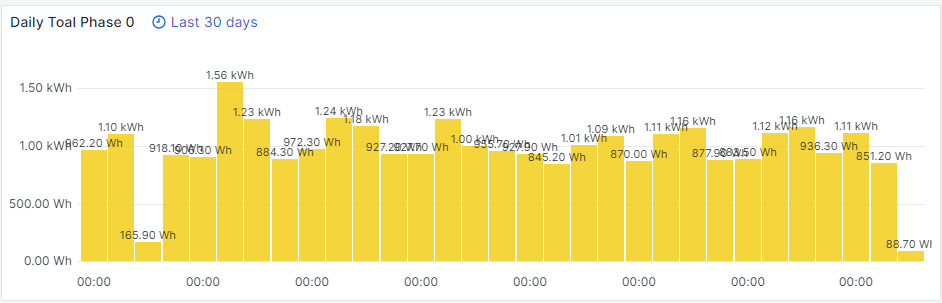
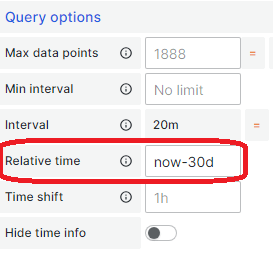
Ich sammel in einem Measurement die Tageswerte meiner Stromphasen. In folgendem Beispiel lasse ich mir den Tagesverbrauch in den letzten 30 Tagen anzeigen. Zuerst gebe ich die verwendete Zeitzone an, da InfluxDB mit GMT, bzw. Epoch (Unix Timestamp) arbeitet. Somit ist auch sichergestellt, das die Zeiten passen. In meinem aggregateWindow lasse ich die Daten für einen Tag auswerten (1d) und den letzten Wert ausgeben (last). In Grafana vergebe ich dann noch einen festen Abfragezeitraum (now-30d) unter die Query options. Somit habe ich eine schöne 30 Tage Übersicht.
import "timezone"
option location = timezone.location(name: "Europe/Berlin")
from(bucket: "shellyshort")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "3em")
|> filter(fn: (r) => r["_field"] == "today")
|> filter(fn: (r) => r["phase"] == "phase0")
|> aggregateWindow(every: 1d, fn: last, createEmpty: false)
|> yield(name: "last")Ok, ich höre schon eure Frage: Wie bekommst du den die Tageswerte? Im Endeffekt ist es relativ einfach. Ihr lest den letzten und ersten Wert und bildet das Delta. Mehr passiert in der unteren Abfrage nicht. Anstelle pro Tag (1d), könnt ihr das natürlich auch für ein Jahr (1y) machen.
import "timezone"
option location = timezone.location(name: "Europe/Berlin")
Last = from(bucket: "shelly")
|> range(start: today())
|> filter(fn: (r) => r["_measurement"] == "3em")
|> filter(fn: (r) => r["_field"] == "total")
|> filter(fn: (r) => r["phase"] == "phase0")
|> aggregateWindow(every: 1d, fn: last, createEmpty: false)
First = from(bucket: "shelly")
|> range(start: today())
|> filter(fn: (r) => r["_measurement"] == "3em")
|> filter(fn: (r) => r["_field"] == "total")
|> filter(fn: (r) => r["phase"] == "phase0")
|> aggregateWindow(every: 1d, fn: first, createEmpty: false)
Delta = join(tables: {Last: Last, First: First}, on: ["_time"])
|> map(fn: (r) => ({r with _delta: r._value_Last - r._value_First}))
|> mean(column: "_delta")
|> yield(name: "delta")Damit sollte ihr erst mal starten können und euere Daten in Grafana visualisieren können. Ich weiß, es erschlägt einen erst mal, aber später hat man es verstanden. Ich kann mir das auch alles nicht merken und kopiere mir das auch immer aus meinen Abfragen zurecht.

Danke für den Einblick und die Darstellung der ersten Schritte mit InfluxDB 2.x und Grafana. Ich war bislang noch immer auf Version 1.x mit FHEM und HomeAssistant und fand die Klickerei in Grafana recht angenehm. Warum man jetzt mit Flux davon abkehrt, verstehe ich gar nicht – es sollte doch auch hier möglich sein, in Grafana zusammenklickbare Abfragen zu gestalten – geht ja im Data-Explorer auch … Deine Seite hat mir jedenfalls geholfen, die ersten Ergebnisse zu realisieren! Grüße …