
Bereits im Jahr 2017 hatte ich einen Artikel zu InfluxDB und Node-RED verfasst, jedoch behandelt dieser nur die Version 1.x von InfluxDB. Mit InfluxDB V2.x hat sich jedoch einiges verändert und ich muss mal wieder etwas zusammen schreiben. Der Artikel kommt sicherlich für einige etwas zu spät, aber die letzten Monate, bzw. Jahre waren sehr bewegt.
In diesem Artiekl gehe ich davon aus, das ihr bereits Node-RED und InfluxDB erfolgreich installiert habt.
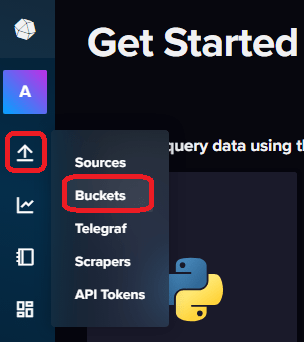
Bucket in InfluxDB erstellen
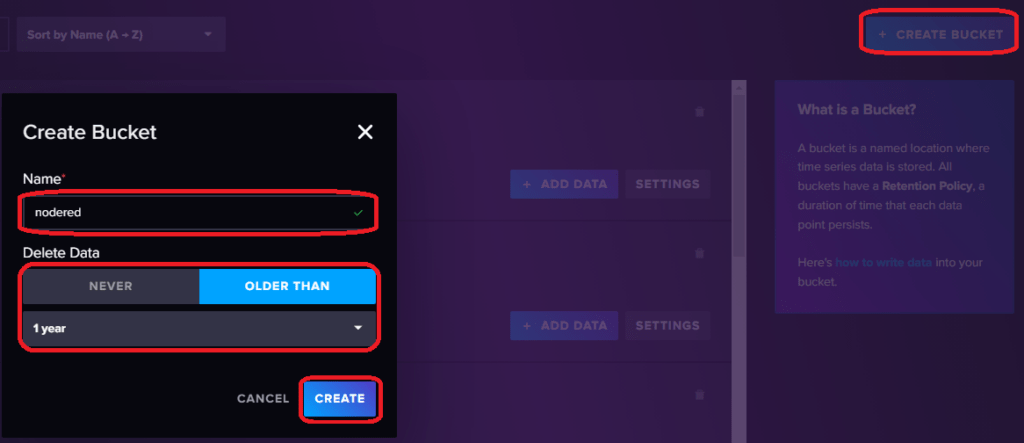
Was früher eine Datenbank war, nennt sich nun Bucket. Die Daten werden also in Eimer gespeichert. Ich verwende das Web UI und zeige euch wie ihr einen Bucket erstellen könnt. Nehmt euren Browser und öffnet das Webinterface eurer InfluxDB Instanz unter http://ip-eures-influxdb-servers:8086 und loggt euch ein. Den Bucket erstellt ihr unter Load Data -> BUCKETS. Wählt einen Namen und eure Retention Period, also die Zeit nachdem eure Datengelöscht werden. Ihr habt hier die Wahl zwischen nie und nach einer bestimmten Zeit.
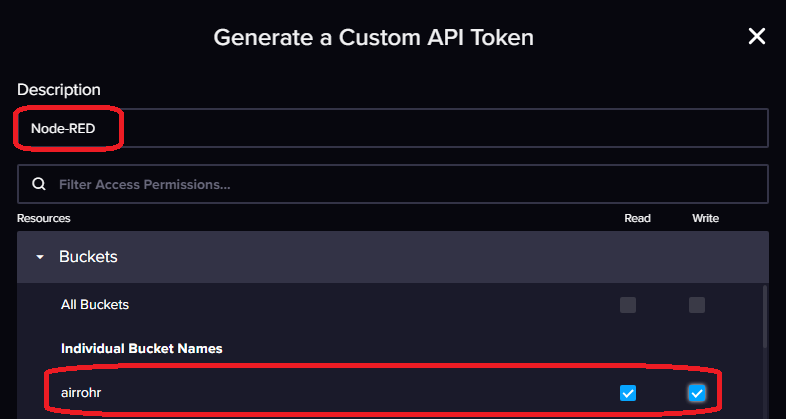
Nun müssen wir noch einen Api Token erzeugen, damit wir Node-RED die Berechtigung zum Lesen und Schreiben erteilen können. Unter API TOKENS könnt ihr ein neues Token erstellen. Ihr solltet dabei „Custom API Token wählen“. Ihr könnt zwar ein „All Access Token“ erzeugen, das ist aber sicherheitstechnisch nicht empfehlenswert. Ihr solltet pro Anwendung ein Token vergeben, mit nur den benötigten Rechten. Wählt also „Custom API Token“ und vergebt einen Namen. Unter Ressources wählt ihr euren Bucket und vergebt mindestens die Write Permission. Anschließend bestätigt ihr mit Generate. Da ich auch Node-RED nutze, um Daten aus InfluxDB zu lesen, habe ich ebenfalls die Reads Permission vergeben. Eine Anwendung für die ihr ebenfalls ein Token erzeugen könnt, ist Grafana. Hier reicht die Read-Permission. Kopiert euch das nun angezeigt API Token, denn dieses ist quasi das Passwort welches Node-RED, für den Zugriff auf InfluxDB, nutzen wird.


Node-RED konfigurieren
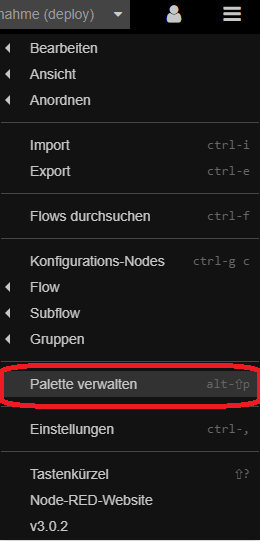
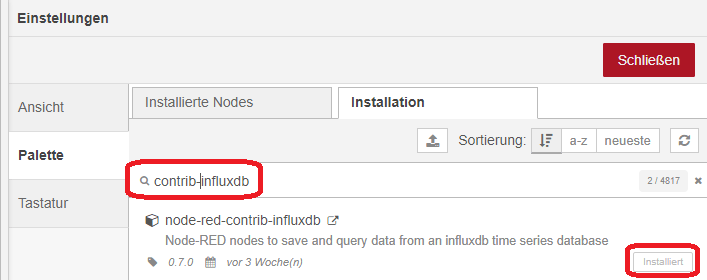
Um überhaput auf die InfluxDB zugreifen zu können, müssen wir erst noch ein paar Nodes nachinstallieren. Wählt „Palette verwalten“ und sucht im Reiter Installation nach contrib-influxdb.Installiert den entsprechenden Node.
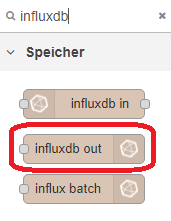
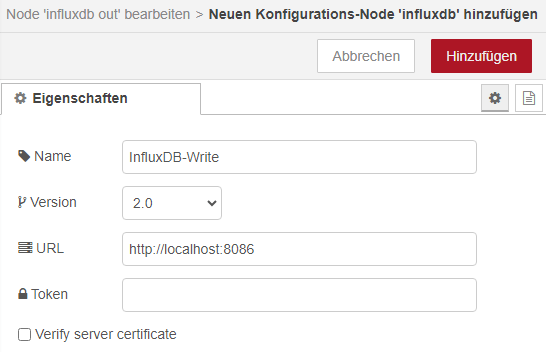
Nun können wir unseren ersten Node hinzu fügen. Wählt dazu den Node „influxdb out“ und erstellt eine neue Konfiguration. Vergebt einen Namen und wählt Version 2.0 aus. Unter URL tragt ihr die IP eures InfluxDB-Servers ein und tragt das vorher erstellte Token ein. Bestätigt dieses mit „Hinzufügen“. Da wir eine InfluxDB V2.x ausgewählt haben, müssen wir nun noch die Organisation eintragen. Diese habt ihr bei der Installation von InfluxDB festgelegt. Ebenfalls müssen wir den Bucket auswählen. Das Measurement können wir hier vergeben, müssen es aber nicht. Ich werde auf beide Fälle später eingehen.
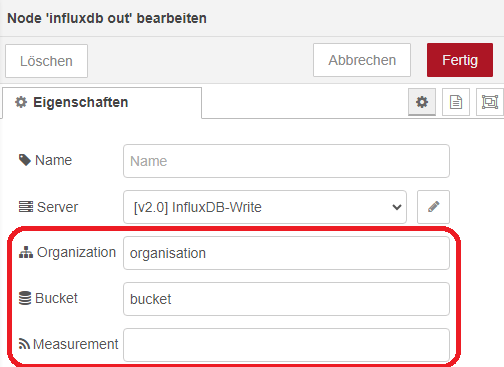
Daten übergeben mit festgelegtem Measurement an InfluxDB
Wir nehmen als Beispiel ein Thermometer, dessen Daten ihr mittels Node-RED abfragt und nun in einer Datenbank speichern wollt. Wir nutzen hier den statisch gesetzten Measurement Namen im InfluxDB-Node. Der entsprechende Funktions-Node kann so aussehen:
var msg1 = {};
var msg2 = {};
var msg3 = {};
var msg4 = {};
msg1.payload = msg.payload.temperature;
msg2.payload = msg.payload.humidity;
msg3.payload = msg.payload.pressure;
msg4.payload = [{"Temperature": msg1.payload, "Humidity": msg2.payload, "Pressure": msg3.payload}];
return msg4;
Es geht auch einfacher und schöner, ich wollte aber mal zeigen wie ich angefangen habe 😉
msg.payload = [{
Temperature: msg.payload.temperature,
Humidity: msg.payload.humidity,
Pressure: msg.payload.pressure
}];
return msg;Daten übergeben ohne festes Measurement
Jetzt habt ihr aber nicht nur ein Thermometer, sondern mehrere. Natürlich könnt ihr mehrere InfluxDB-Nodes anlegen und jeweils einen anderes Measurement auswählen, aber ihr könnt auch das Measurement im Funktions-Node übergeben. So spart ihr euch Nodes und alles ist übersichtlicher. Ihr habt z.B. einen Bucket Klima und speichert dort verschiedene Measurements.
msg.payload = [{
Temperature: msg.payload.temperature,
Humidity: msg.payload.humidity,
Pressure: msg.payload.pressure
}];
msg.measurement = "Wohnzimmer";
return msg;Wenn ihr die Daten lesen wollt, würde eine entsprechende Abfrage auf die InfluxDB so aussehen können:
from(bucket: "Klima")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "Wohnzimmer")
|> filter(fn: (r) => r["_field"] == "Temperature")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")In der Abfrage macht sich auch der große Unterschied zu dem V1.x InfluxDB ersichtlich. Die Abfragen sind nicht mehr SQL-Like sondern in der eigenen Syntax Flux.
Daten übergeben mit Tags
Wenn ihr eure Daten vorher schon alle in Node-RED in Variablen ableget habt, könnt ihr auch alles in einem Rutsch übergeben und die Räume mittels Tags differenzieren. So etwas könnte dann so aussehen:
msg.payload = [
[{
temperature: msg.payload.wz.temperature,
humidity: msg.payload.wz.humidity
},
{
raum: "Wohnzimmer"
}],
[{
temperature: msg.payload.bz.temperature,
humidity: msg.payload.bz.humidity
},
{
raum: "Badezimmer"
}]
];
msg.measurement = "Klima";
return msg;Eine entsprechende Abfrage auf die DB sehe dann so aus:
from(bucket: "Messwerte")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "Klima")
|> filter(fn: (r) => r["raum"] == "Wohnzimmer")
|> filter(fn: (r) => r["_field"] == "temperature")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")So habt ihr dann einen Bucket „Messwerte“ in dem ihr ein Measurement für das Klima habt und nicht mehr eines für jeden Raum. In dem Measurement sind die einzelnen Messwerte, welche durch ein Tag namens „raum“ unterscheidbar sind.
Ihr seht viele Wege führen nach Rom und ihr müsste selber entscheiden wie ihr eure Daten strukturieren wollt. Mit der Zeit und Erfahrung wird sich auch euere Herangehensweise verändern. Wie ihr seht, ist es relativ einfach Daten zu schreiben, jedoch das Abfragen ist komplett anders als vorher. Ich denke mal dazu werde ich auch noch einen Beitrag erstellen, damit ihr auch etwas mit euren Daten machen könnt.
Hallo Bjoern. Danke, ist eine tolle Anleitung. Ich bekomme mittels mqtt in Intervallen von 20-50 Sekunden einen Wert geliefert, der den Ladezustand meiner Balkonkraftwerk-Batterie zeigt.
Es würde aber reichen wenn ich den Wert nur alle 5 Minuten in die influxdb schreibe. Hast du eine Idee wie ich das umsetzen könnte ( in nodered) ?
Danke
Lg Joe
Hi, über den Delay Node kannst du das realisieren. Eine Nachricht pro 5 Minuten und dann sollte es passen.
Grüße, Björn
Hallo,
sorry für die vielleicht dumme Frage.
Ich habe mir die InfluxDB wie beschrieben eingerichtet.
1) Organisation: xxxx
2) Bucket: yyyy
Für das Bucket „yyyy“ habe ich einen API-Token generiert.
Im NodeRed habe ich den „influx-out“ genommen und meinen Influxserver angelegt (Influx Version 2 URL: http://:8086 und den API-Token eingefügt)
Dann die Organisation = „xxxx“ und Bucket = „yyyy“ eingetragen – Messurement ist leer.
Soweit s o gut nur dass mir NodeRed folgen Nachricht wirft: „HttpError: unauthorized access“
Evtl eine Idee? – ich würde mich über einen Tipp sehr freuen – danke
Hi,
wenn du kein festes Measurement setzt, musst du spätestens das Measurement im Funktions-Node übergeben:
msg.measurement = „dein-measurement“;
Grüße,
Björn